28/08/23. Ya no es noticia que la Inteligencia Artificial está teniendo un fuerte impacto en todos los sectores, incluyendo el sector porcino. Durante las próximas semanas, y a través de una serie de artículos, iremos explicando de lo más sencillo a lo más complicado, para que cualquier persona que trabaje en el sector porcino pueda hacerse una idea de cómo funciona la Inteligencia Artificial, cómo le puede ayudar en su día a día, y cómo puede contribuir a que su empresa aproveche todo el potencial de la Inteligencia Artificial. No lo haremos desde un punto de vista teórico, sino desde un punto de vista práctico, poniendo pequeños ejemplos que todo el mundo pueda entender. Nosotros trabajamos todos los días con Inteligencia Artificial, cosa que nos apasiona. A veces es un poco difícil expresar lo que hacemos con palabras sencillas, pero vamos a intentarlo. Si uno se lee la definición que la Wikipedia hace de la Inteligencia Artificial… pues igual se queda un poco igual! Es tan amplia y heterogénea que es difícil saber qué exactamente. Aquí iremos poco a poco, y si te quedas hasta el final seguro que acabas llevándote una idea clara.
28/08/23. Ya no es noticia que la Inteligencia Artificial está teniendo un fuerte impacto en todos los sectores, incluyendo el sector porcino. Durante las próximas semanas, y a través de una serie de artículos, iremos explicando de lo más sencillo a lo más complicado, para que cualquier persona que trabaje en el sector porcino pueda hacerse una idea de cómo funciona la Inteligencia Artificial, cómo le puede ayudar en su día a día, y cómo puede contribuir a que su empresa aproveche todo el potencial de la Inteligencia Artificial. No lo haremos desde un punto de vista teórico, sino desde un punto de vista práctico, poniendo pequeños ejemplos que todo el mundo pueda entender. Nosotros trabajamos todos los días con Inteligencia Artificial, cosa que nos apasiona. A veces es un poco difícil expresar lo que hacemos con palabras sencillas, pero vamos a intentarlo. Si uno se lee la definición que la Wikipedia hace de la Inteligencia Artificial… pues igual se queda un poco igual! Es tan amplia y heterogénea que es difícil saber qué exactamente. Aquí iremos poco a poco, y si te quedas hasta el final seguro que acabas llevándote una idea clara.
Lo primero, datos
 Hay muchos caminos para mejorar nuestras explotaciones porcinas, pero los mejores suelen estar basados en datos. Aunque el manejo de seres vivos es un arte, la mejor manera de validar nuestras intuiciones es recopilando datos. A veces, estos datos pueden estar anotados en una simple hoja en la entrada de una nave. Otras veces, recogerse a través de una excel o aplicación. En aplicaciones más avanzadas, que se dan cada vez más frecuentemente, los datos se generan solos y en tiempo real. Estamos hablando de dispositivos IoT (Internet de las cosas). Es decir, de dispositivos electrónicos que actúan cómo sensores y transmiten su información hacia internet, donde podemos consultarla y sacarle partido. Un tema importante, que trataremos en su momento, es cómo realizar un despliegue resiliente y sobre todo, seguro, de una flota de dispositivos IoT. Es decir, cuando hacemos pequeñas pruebas con un sensor, igual la seguridad no es una prioridad, pero cuando una gran integradora porcina se plantea un despliegue masivo de sensórica, debe tener en cuenta muchas cuestiones empezando por la seguridad. Pero bueno, no nos adelantemos, trataremos el tema de la seguridad en su momento.
Hay muchos caminos para mejorar nuestras explotaciones porcinas, pero los mejores suelen estar basados en datos. Aunque el manejo de seres vivos es un arte, la mejor manera de validar nuestras intuiciones es recopilando datos. A veces, estos datos pueden estar anotados en una simple hoja en la entrada de una nave. Otras veces, recogerse a través de una excel o aplicación. En aplicaciones más avanzadas, que se dan cada vez más frecuentemente, los datos se generan solos y en tiempo real. Estamos hablando de dispositivos IoT (Internet de las cosas). Es decir, de dispositivos electrónicos que actúan cómo sensores y transmiten su información hacia internet, donde podemos consultarla y sacarle partido. Un tema importante, que trataremos en su momento, es cómo realizar un despliegue resiliente y sobre todo, seguro, de una flota de dispositivos IoT. Es decir, cuando hacemos pequeñas pruebas con un sensor, igual la seguridad no es una prioridad, pero cuando una gran integradora porcina se plantea un despliegue masivo de sensórica, debe tener en cuenta muchas cuestiones empezando por la seguridad. Pero bueno, no nos adelantemos, trataremos el tema de la seguridad en su momento.
Primeros análisis, excel y grupo control
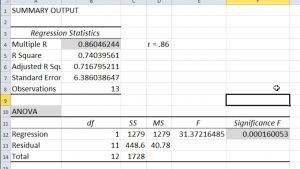 Con un pequeño conocimiento de estadística y un buen manejo de excel se pueden hacer unos primeros análisis… que muchas veces ya son mucho, si es la primera vez que se dispone de datos. Por ejemplo, en excel podemos ver en gráfico dinámico la evolución del índice de conversión y ganancia media diaria para una nueva fórmula de pienso porcina y su grupo control (un grupo de animales no tratados con la nueva fórmula). Con ello podemos saber si la fórmula, en las circunstancias en las que ha sido probada, nos es de utilidad. Excel tiene sus perlas ocultas, como su plugin de análisis de datos, o recientemente la posibilidad de ejecutar código python! Con ello, la propia excel nos puede calcular una estadística descriptiva básica o un p-value (una medida estadística bastante usada para decidir si un experimento ha salido como esperábamos o los resultados son puro azar).
Con un pequeño conocimiento de estadística y un buen manejo de excel se pueden hacer unos primeros análisis… que muchas veces ya son mucho, si es la primera vez que se dispone de datos. Por ejemplo, en excel podemos ver en gráfico dinámico la evolución del índice de conversión y ganancia media diaria para una nueva fórmula de pienso porcina y su grupo control (un grupo de animales no tratados con la nueva fórmula). Con ello podemos saber si la fórmula, en las circunstancias en las que ha sido probada, nos es de utilidad. Excel tiene sus perlas ocultas, como su plugin de análisis de datos, o recientemente la posibilidad de ejecutar código python! Con ello, la propia excel nos puede calcular una estadística descriptiva básica o un p-value (una medida estadística bastante usada para decidir si un experimento ha salido como esperábamos o los resultados son puro azar).
Sin embargo, hemos de tener cuidado. Los científicos de datos, las personas que se dedican de manera profesional a analizar datos, para cada tipo de análisis hacen antes una serie de validaciones que son necesarias para garantizar que el análisis está bien hecho. Si esas validaciones no se cumplen, el análisis no se puede aplicar. Son validaciones típicas la independencia, normalidad, homogeneidad, variables de confusión, diseño experimental, tamaño muestral, control de variables externas, y tendencias temporales. Para cada una de estas cuestiones, los científicos de datos hacen un análisis matemático sobre los datos, que les garantiza que vamos a obtener las respuestas que queremos obtener… y lamentablemente en muchos experimentos estas condiciones no se cumplen y los resultados pueden estar diciéndonos justo lo contrario que lo que entendemos!
Liándola parda
 Veámoslo con nuestro ejemplo. Imaginemos que en nuestro experimento sobre formulaciones se analizan los datos y se obtiene un p-value < 0.001. Esto significa que el experimento ha ido muy bien, realmente bien, tenemos una nueva fórmula que a partir de ahora aplicaremos a miles de animales y nos hará ganar mucho dinero! Sin embargo, tras analizar las condiciones del experimento, resulta que durante el período del mismo hubo fluctuaciones significativas en las condiciones ambientales, como la temperatura y la humedad. Estas condiciones ambientales pueden influir en el aumento de peso de los cerdos de manera independiente de la dieta que están recibiendo.
Veámoslo con nuestro ejemplo. Imaginemos que en nuestro experimento sobre formulaciones se analizan los datos y se obtiene un p-value < 0.001. Esto significa que el experimento ha ido muy bien, realmente bien, tenemos una nueva fórmula que a partir de ahora aplicaremos a miles de animales y nos hará ganar mucho dinero! Sin embargo, tras analizar las condiciones del experimento, resulta que durante el período del mismo hubo fluctuaciones significativas en las condiciones ambientales, como la temperatura y la humedad. Estas condiciones ambientales pueden influir en el aumento de peso de los cerdos de manera independiente de la dieta que están recibiendo.
Al no considerar estas condiciones ambientales como posibles factores de confusión, los investigadores pasaron por alto una variable importante que podría estar afectando los resultados. En otras palabras, no verificaron si se cumplían las condiciones para realizar una prueba t válida, que incluyen la suposición de que los datos sean independientes y se distribuyan normalmente. En este escenario, aunque el p-value fue muy pequeño y llevó a rechazar la hipótesis nula, las conclusiones son incorrectas. El resultado podría ser debido en parte o completamente a las variaciones en las condiciones ambientales en lugar de a la dieta en sí. Si los investigadores hubieran realizado un análisis más completo, considerando las condiciones ambientales como variables de control o realizando pruebas de normalidad en los datos, podrían haber llegado a conclusiones más precisas y ajustadas a la realidad.
Conclusiones
Este ejemplo destaca la importancia de no solo realizar análisis estadísticos, sino también de verificar y cumplir con las condiciones previas necesarias para que los resultados sean confiables y las conclusiones sean válidas. Otra manera de decirlo es que quizás para análisis importantes es bueno apoyarse en expertos matemáticos y estadísticos que nos aseguren que estamos interpretando los datos correctamente. También nos introduce a un problema importante, que al fin y al cabo es a dónde queremos llegar con esta serie de artículos… ¿Cómo podemos analizar a la vez una gran cantidad de variables que influyen en los datos que queremos analizar? Esto nos llevará, aunque aún nos falta algo de camino por recorrer, a la Inteligencia Artificial, el Deep learning y los modelos predictivos.
Este artículo es el primero de una serie de artículos publicados por la startup IA Sapiens dedicada a explicar qué es la Inteligencia Artificial en el sector porcino. En el siguiente artículo, iremos un poco más allá de nuestra hoja Excel y pasaremos a analizar el uso de herramientas de inteligencia empresarial y de ciencia de datos.